字符集基础
对于计算机而言,它仅认识两个0和1,不管是在内存中还是外部存储设备上,我们所看到的文字、图片、视频等等“数据”在计算机中都是已二进制形式存在的。不同字符对应二进制数的规则,就是字符的编码。字符编码的集合称为字符集。
常见字符编码
计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。常见的字符编码主要包括:ASCII编码、GB**编码、Unicode。
1.ASCII编码
ASCII,American Standard Code for Information Interchange,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统。
ASCII收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的附加符号字母,故可以使用ASCII及控制字符以外的区域来储存及表示。
扩充ASCII制定了十多个适用于不同国家和地区(均为拉丁字符集(高位为1的8位代码),称为ISO8859,又称为 扩充ASCII字符集
Latin1是ISO-8859-1的别名
2.GBK***编码
ASCII最大的缺点就是显示字符有限,他虽然解决了部分西欧语言的显示问题,但是对更多的其他语言他实在是无能为了。随着计算机技术的发展,使用范围越来越广泛了,ASCII的缺陷越来越明显了,其他国家和地区需要使用计算机,必须要设计一套符合本国/本地区的编码规则。例如为了显示中文,我们就必须要设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。
GB2312,用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆。
GBK,汉字编码标准之一,全称《汉字内码扩展规范》,它 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1 国际标准,是前者向后者过渡过程中的一个承上启下的标准。
3.Unicode编码
正如前面前面所提到的一样,世界存在这么多国家,也存在着多种编码风格,像中文的GB232、GBK、GB18030,这样乱搞一套,虽然在本地运行没有问题,但是一旦出现在网络上,由于互不兼容,访问则会出现乱码。为了解决这个问题,伟大的Unicode编码腾空出世。
Unicode编码又称统一码、万国码、单一码,它是业界的一种标准,是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。同时Unicode是字符集,它存在很多几种实现方式如:UTF-8、UTF-16.
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍:UTF-8是Unicode的实现方式之一。
转载请注明来源:字符集基础
周sir
这家伙很懒,什么都没写!
你可能也喜欢

常用数据库连接池 (DBCP、c3p0、Druid) 配置说明
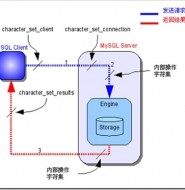
MySQL字符集设置

Mysql存储引擎
Mysql5.7下载安装与配置






![AOP 那点事儿[续]](http://www.yuguoxy.com/geekhome/wp-content/themes/Enews/timthumb.php?src=http://www.yuguoxy.com/geekhome/wp-content/uploads/2017/11/微信截图_20200508200107.png&h=60&w=67&zc=1)